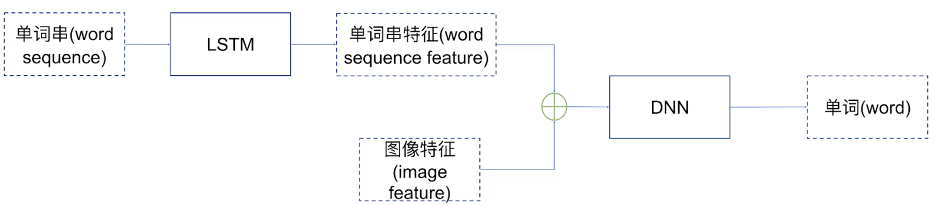
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| def create_input_data(tokenizer, max_length, descriptions, photos_features, vocab_size):
"""
从输入的图片标题list和图片特征构造LSTM的一组输入
Args:
:param tokenizer: 英文单词和整数转换的工具keras.preprocessing.text.Tokenizer
:param max_length: 训练数据集中最长的标题的长度
:param descriptions: dict, key 为图像的名(不带.jpg后缀), value 为list, 包含一个图像的几个不同的描述
:param photos_features: dict, key 为图像的名(不带.jpg后缀), value 为numpy array 图像的特征
:param vocab_size: 训练集中表的单词数量
:return: tuple:
第一个元素为 numpy array, 元素为图像的特征, 它本身也是 numpy.array
第二个元素为 numpy array, 元素为图像标题的前缀, 它自身也是 numpy.array
第三个元素为 numpy array, 元素为图像标题的下一个单词(根据图像特征和标题的前缀产生) 也为numpy.array
Examples:
from pickle import load
tokenizer = load(open('tokenizer.pkl', 'rb'))
max_length = 6
descriptions = {'1235345':['startseq one bird on tree endseq', "startseq red bird on tree endseq"],
'1234546':['startseq one boy play water endseq', "startseq one boy run across water endseq"]}
photo_features = {'1235345':[ 0.434, 0.534, 0.212, 0.98 ],
'1234546':[ 0.534, 0.634, 0.712, 0.28 ]}
vocab_size = 7378
print(create_input_data(tokenizer, max_length, descriptions, photo_features, vocab_size))
(array([[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.434, 0.534, 0.212, 0.98 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ],
[ 0.534, 0.634, 0.712, 0.28 ]]),
array([[ 0, 0, 0, 0, 0, 2],
[ 0, 0, 0, 0, 2, 59],
[ 0, 0, 0, 2, 59, 254],
[ 0, 0, 2, 59, 254, 6],
[ 0, 2, 59, 254, 6, 134],
[ 0, 0, 0, 0, 0, 2],
[ 0, 0, 0, 0, 2, 26],
[ 0, 0, 0, 2, 26, 254],
[ 0, 0, 2, 26, 254, 6],
[ 0, 2, 26, 254, 6, 134],
[ 0, 0, 0, 0, 0, 2],
[ 0, 0, 0, 0, 2, 59],
[ 0, 0, 0, 2, 59, 16],
[ 0, 0, 2, 59, 16, 82],
[ 0, 2, 59, 16, 82, 24],
[ 0, 0, 0, 0, 0, 2],
[ 0, 0, 0, 0, 2, 59],
[ 0, 0, 0, 2, 59, 16],
[ 0, 0, 2, 59, 16, 165],
[ 0, 2, 59, 16, 165, 127],
[ 2, 59, 16, 165, 127, 24]]),
array([[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]]))
"""
pass
|