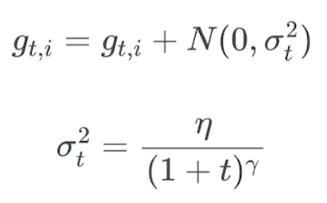梯度下降法
- 梯度下降法是训练神经网络最常用的优化算法
- 梯度下降法(Gradient descent) 是一个一阶最优化算法,通常也称为最速下降法。要使用梯度下降法找到一个函数的局部最小值,必须想函数上当前点对应的梯度(或者是近似梯度)的反方向的规定部长距离点进行迭代搜索。
- 梯度下降法基于以下的观察:如果实值函数在a点处可微并且有定义,那么函数在点a沿着梯度相反的方向下降最快
偏导数
对于一个多元函数,比如,计算偏导数:
将不求的部分当做常数,其他部分求导即可。
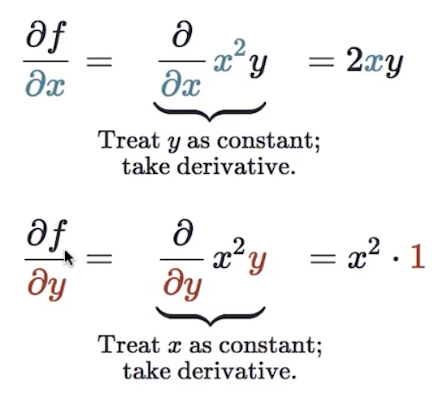
梯度
The gradient of a scalar-valued multivariable function,denoted,packages all its partial derivative information into a vector:
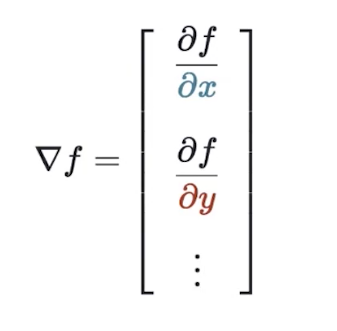
这就意味着是一个向量。
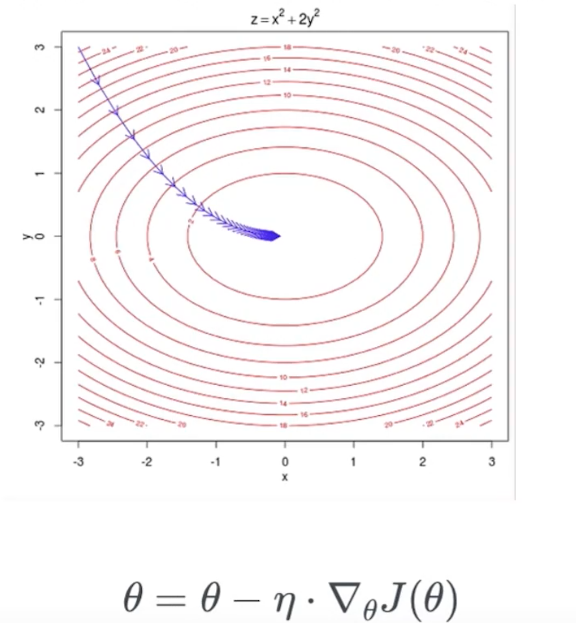
梯度下降算法
在每一个点计算梯度,向梯度相反的方向移动指定的步长,到达下一个点后重复上述操作。
批处理梯度下降法
有两层循环,伪代码如下:
1 | for i in range (nb_epochs): |
特点
- 在凸优化(Convex Optimization)的情况下,一定会找到最优解
- 在非凸优化的情况下,一定能找到局部最优解
- 单次调整计算量大
- 不适合在线(Online)情况
随机梯度下降法
有两层循环,伪代码如下:
1 | for i in range(nb_epochs): |
与批处理相比,梯度更新在第二个循环内部,所以参数更新次数增多了。
每一次循环前有一次shuffle,遍历的顺序是随机的。
特点
- 适合Online的情况
- 通常比批处理下降法快(在批处理的情况下,有可能许多数据点产生的梯度是相似的,属于冗余运算,并没有实际帮助)
- 通常目标函数震荡严重,在神经网络优化情况下(没有全局最优解),这种震荡反而有可能让它避免被套牢在一个局部最小值,而找到更好的局部最优解

- 通过调整学习率,能够找到和批处理相似的局部或者全局最优解
迷你批处理梯度下降法
有三层循环,伪代码如下:
1 | for i in range(nb_epochs): |
特点
- 结合了批处理和随机梯度下降法的优点
- 减弱了目标函数震荡,更加稳定
- 易于硬件加速实现,常用的机器学习库都利用了这个特性提供了高性能的计算速度(mini批可能能够放入GPU显存或者内存)
- 一般的迷你批大小位50至256,取决于不同的应用
传统梯度下降法面临的挑战
- 传统迷你批处理不能保证能够收敛
- 当学习率太小,收敛会很慢,学习率太高,容易震荡,甚至无法收敛
- 可以按照某个公式随着训练逐渐减小学习率,但是不同数据集需要不同的学习率变化曲线,不容易估计
- 所有的参数使用同样的学习率并不合适
- 容易被套牢在马鞍点(Saddle point)
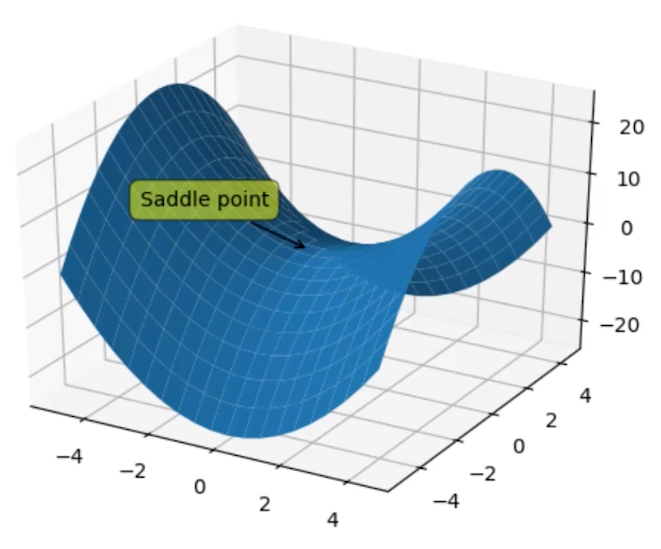
马鞍点
在马鞍点处,梯度为0,但是不是最优解。不同算法有些能够逃离,有些不能逃离。
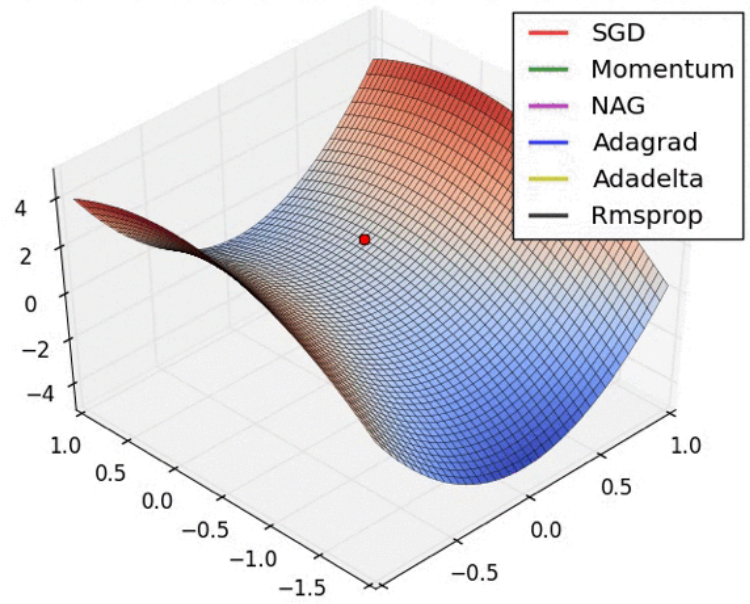
在这种马鞍点中,Adadelta较容易逃离,NAG、Rmsprop、Adagrad、Momentum都可以逃离,随机梯度下降法(SGD)无法逃离。
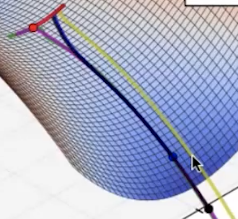
常见的梯度下降法
Momentu(动量法)
- 不同的dimension的变化率不一样
- 动量在梯度的某一纬度上的投影只想同一方向上的增强,在纬度上的指向不断变化的方向抵消
*
以中药碾子为例:

假设中心凹槽为曲面,那么最优值应该在中心位置:
如果不引入Momentum,那么训练过程中,移动方向会不断向两侧跳跃:

如果引入Momentum:

为什么能达到这样的效果
将曲面画作山谷形状,理想情况下是蓝色曲线的路径:
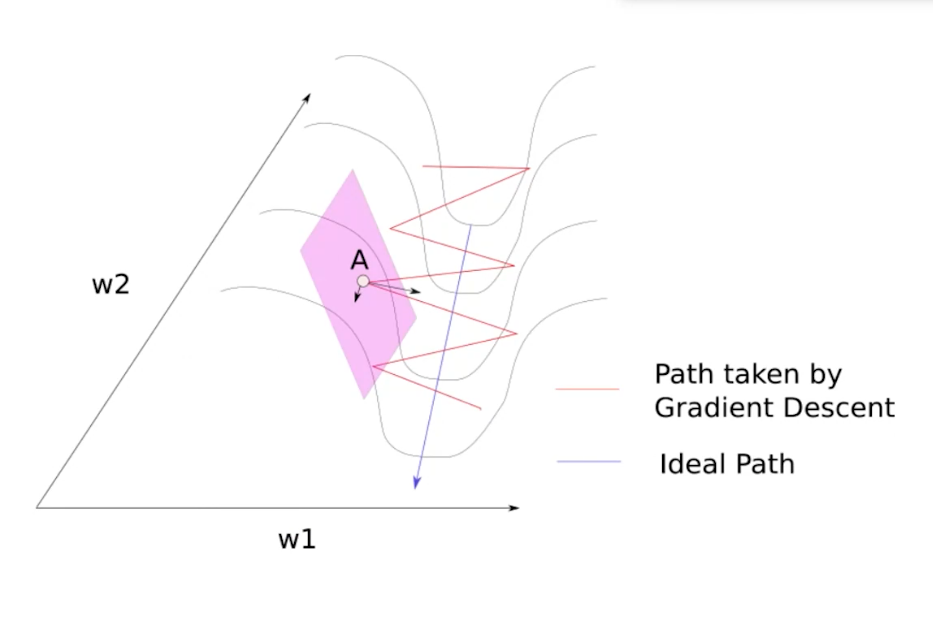
但是在传统算法,那么运动的曲线为红色曲线。如果我们将每一个点按照参数方向进行分解:
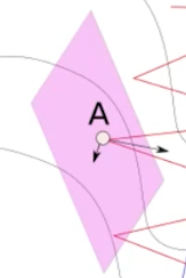
在每一点都进行分解:
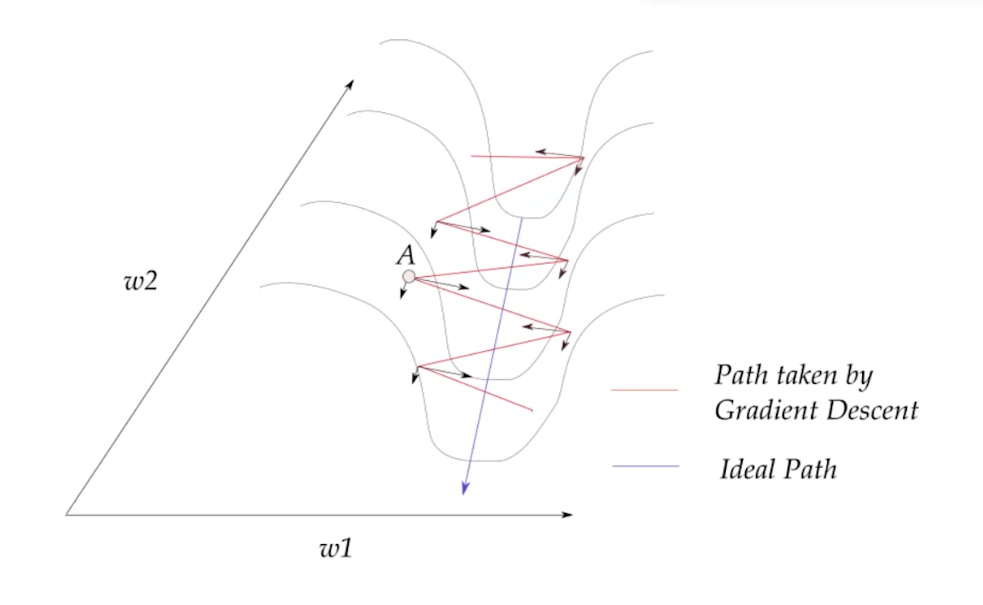
可以看到,任何一点都有一个分方向与最优方向同向,另一个分方向会与下一个分方向部分抵消。这样最优方向的分向会增加,其他方向会逐渐抵消。
Nesterov accelerated gradient
- 动量+预测前方的梯度
- 在多个RNN任务中表现突出
*
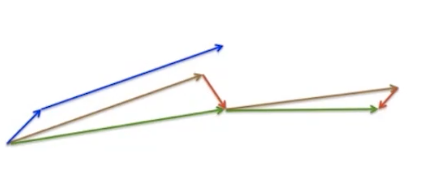
小结
上面两种优化算法都是对梯度本身的优化,整体优化,下面的几种方法将采用对参数“各个击破的方式”来实现优化。
Adagrad
- 对重要性高的参数,采用小的步长
- 对相对不重要的参数,采用大的步长
- 对稀疏数据集非常有效(文本数据)。Google在训练从Youtube识别自动识别猫采用的就是这种方法,Pennington et al训练词嵌入的GloVe也采用的这种方法
实现方法
关键在于分母,是一个对角矩阵,d表示参数的个数。表示第个参数位置的值
为了防止G为0,加入另外一个很小的值
优势
- 无需手动调整步长
- 设置初始值为0.01即可
劣势
- 随着训练,步长总是越来越小
Adadelta
- 只累积过去一段时间的梯度平方值
- 完全无需设置步长
- 为了便于实现,采用类使用动量的策略:
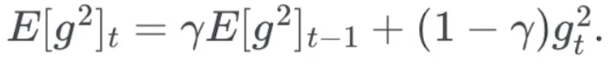
实现方法
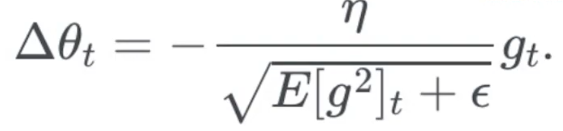
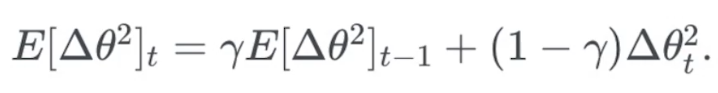
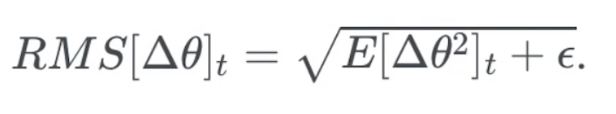
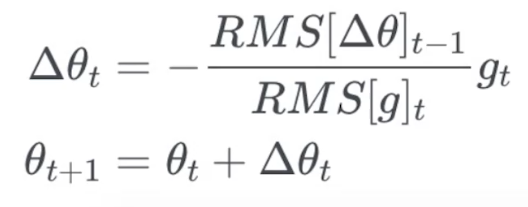
RMSprop
与上面两种方法几乎一致,把过去结果乘0.9,当前结果乘0.1
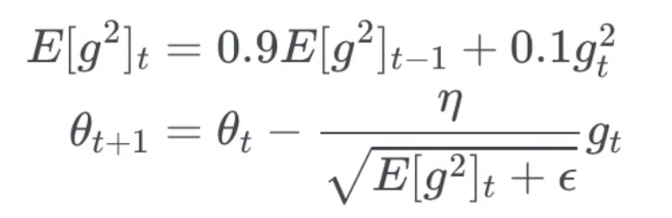
公式不同,思路相似
Adam
- 使用最广泛的方法
- 记录一段时间的梯度平方和(累死Adadelta和RMSprop),以及梯度的和(类似Momentum动量)
- 把优化看做铁球滚下山坡,Adam定义了一个带动量和摩擦的铁球
实现方法
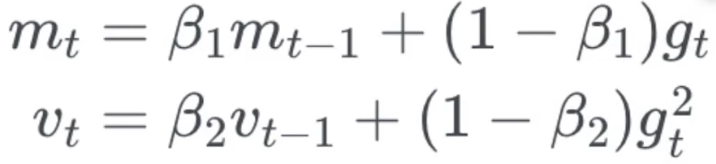
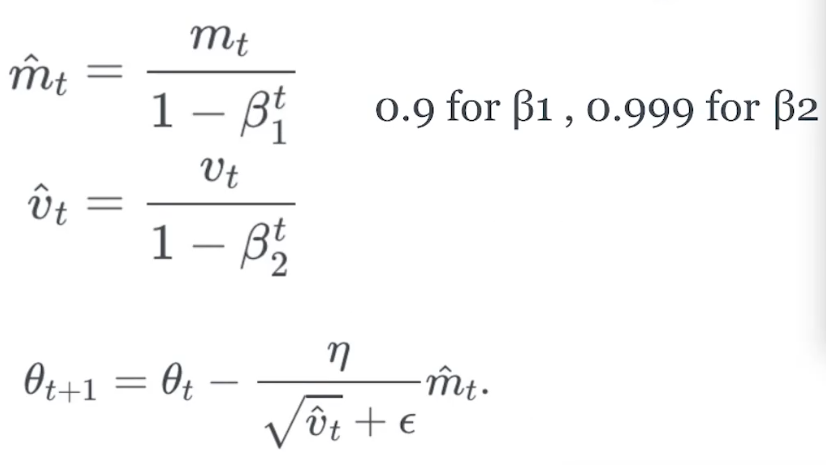
更新权值采用原来的权值减去某一梯度的变形
如何选择
- 如果数据集是稀疏的,选择自适应学习率的方法会更快的收敛
- RMSprop,Adadelta,Adam的效果非常相似,大多数情况下Adam略好
小技巧
每一个epoch之前重新洗牌数据
使用Batch Normalization
- 我们一般会对训练数据做正则化,但是随着数据的前馈,后面layers的输入已经不是正则化的了,Batch Normalization就是在后面layer之间做正则化
- 使得训练可使用更大的学习率,layer参数的初始化可以更加随意
- BN还有regularization的作用,可以减少对Dropout的依赖
Early Stopping:Early stopping (is) beautiful free lunch (NIPS 2015 Tutorial slides ,slide 63)
增加随机噪声到梯度
- 使得layer参数初始化更加随意
- 使得model可以找到新的局部最小值